v 2.40 Copyright (C) 1999-2023 Jean-Michel DOUDOUX.
")





| Développons en Java v 2.40 Copyright (C) 1999-2023 Jean-Michel DOUDOUX. |
|||||||
|
|
|
|
|
|
||
 |
 |
 |
| Niveau : | |
La machine virtuelle Java ou JVM (Java Virtual Machine) est un environnement d'exécution pour applications Java.
C'est un des éléments les plus importants de la plate-forme Java. Elle assure l'indépendance du matériel et du système d'exploitation lors de l'exécution des applications Java. Une application Java ne s'exécute pas directement dans le système d'exploitation mais dans une machine virtuelle qui s'exécute dans le système d'exploitation et propose une couche d'abstraction entre l'application Java et ce système.
La machine virtuelle permet notamment :
Son mode de fonctionnement est relativement similaire à celui d'un ordinateur : elle exécute des instructions qui manipulent différentes zones de mémoire dédiées de la JVM.
Une application Java ne fait pas d'appel direct au système d'exploitation (sauf en cas d'utilisation de JNI) : elle n'utilise que les API qui sont pour une large part écrites en Java sauf quelques-unes qui sont natives. Ceci permet à Java de rendre les applications indépendantes de l'environnement d'exécution.
La machine virtuelle ne connaît pas le langage Java : elle ne connaît que le bytecode qui est issu de la compilation de codes sources écrits en Java.
Les spécifications de la machine virtuelle Java définissent :
Les fonctionnalités de la JVM décrites dans les spécifications sont abstraites : elles décrivent les fonctionnalités requises mais ne fournissent aucune implémentation ou algorithme d'implémentation. L'implémentation est à la charge du fournisseur de la JVM. Il existe de nombreuses implémentations de JVM dont les plus connues sont celles de Sun Microsystems/Oracle (HotSpot), IBM (J9), BEA/Oracle (JRockit), Azul (Zing), ...
Le respect strict de ces spécifications par une implémentation de la JVM garantit la portabilité et la bonne exécution du bytecode.
Ces spécifications sont consultables à l'url : https://docs.oracle.com/javase/specs/
Ce chapitre contient plusieurs sections :
Pour faciliter la gestion de la mémoire, Java propose de simplifier la vie des développeurs :
La machine virtuelle Java utilise un processus de récupération automatique de la mémoire des objets inutilisés nommé ramasse-miettes (Garbage Collector en anglais). Les objets inutilisés sont les objets qui ne sont référencés par aucun autre objet.
Ceci évite aux développeurs d'avoir à se soucier de cette récupération dans le code mais présente au moins deux inconvénients :
Le ramasse-miettes est une fonctionnalité de la machine virtuelle qui peut mettre en oeuvre plusieurs algorithmes pour rechercher les objets inutilisés et récupérer automatiquement la mémoire de ces objets. Chaque JVM implémente son propre ramasse-miettes en utilisant un ou plusieurs algorithmes.
Une JVM 32bits utilise un adressage sur 32 bits ce qui lui permet de gérer jusqu'à 4 Go de mémoire.
Les règles de gestion de la mémoire dans une JVM sont définies dans le JMM (Java Memory Model). Initialement ces règles sont définies dans la Java Specification Langage : elles ont été revues dans la JSR 133
Le stockage des données dans la JVM est opéré dans différentes zones réparties en deux grandes catégories :
Plusieurs zones de mémoire sont utilisées par la JVM :
Chaque thread possède sa propre pile qui contient les variables qui ne sont accessibles que par le thread telles que les variables locales, les paramètres, les valeurs de retour de chaque méthode invoquée par le thread.
Seules des données de type primitif et des références à des objets peuvent être stockées dans la pile. La pile ne peut pas contenir d'objets.
La taille d'une pile peut être précisée à la machine virtuelle.
Si la taille d'une pile est trop petite pour les besoins des traitements d'un thread alors une exception de type StackOverflowError est levée.
Si la mémoire de la JVM ne permet pas l'allocation de la pile d'un nouveau thread alors une exception de type OutOfMemoryError est levée.
Cette zone de mémoire est partagée par tous les threads de la JVM : elle stocke toutes les instances des objets créés.
Tous les objets créés sont obligatoirement stockés dans le tas (heap) et sont donc partagés par tous les threads. Comme les tableaux sont des objets en Java, les tableaux sont stockés dans le tas même si ce sont des tableaux de types primitifs.
La libération de cet espace mémoire est effectuée grâce à un mécanisme automatique implémenté dans la JVM : le ramasse-miettes (garbage collector). Le ou les algorithmes utilisés pour l'implémentation du ramasse-miettes sont à la discrétion du fournisseur de la JVM.
La taille du tas peut être fixe ou variable durant l'exécution de la JVM : dans ce dernier cas, une taille initiale est fournie et cette taille peut grossir jusqu'à un maximum défini.
Si la taille du heap ne permet pas le stockage d'un objet en cours de création, alors une exception de type OutOfMemoryError est levée.
Cette zone de la mémoire, partagée par tous les threads, stocke la définition des classes et interfaces, le code des constructeurs et des méthodes, les constantes, les variables de classe (variables static) ...
Comme pour la pile, seules des données de type primitif ou des références à des objets peuvent être stockées dans cette zone de mémoire. La différence est que cette zone de mémoire est accessible à tous les threads. Il est donc important dans un contexte multithread de sécuriser l'accès à une variable static même si elle est de type primitif.
Cette zone de la mémoire stocke le résultat compilé du code des méthodes. La taille par défaut est généralement de 32Mo.
Une classe ou une interface suit un cycle de vie particulier dans la machine virtuelle de son chargement à son retrait.

Chaque étape est dédiée à une tâche spécifique :
- La vérification (verify) permet de s'assurer que le bytecode est compatible avec la machine virtuelle
- La préparation (prepare) effectue l'allocation mémoire nécessaire à la classe
- La résolution (resolve) transforme les références symboliques du constant pool en références mémoire.
La machine virtuelle charge, lie et initialise les classes et interfaces requises à l'exécution.
Le démarrage d'une application commence par le chargement de sa classe principale (celle fournie en paramètre de la JVM)
Toutes les classes utilisées pour l'instanciation de cette classe et celles utilisées dans sa méthode main() sont chargées à leur première utilisation.
Un classloader est un objet qui charge dynamiquement et initialise des classes et interfaces Java requises par la JVM lors de l'exécution d'une application. Un classloader hérite de la classe java.lang.ClassLoader.
Un classloader effectue généralement plusieurs opérations pour charger une classe :
Le chargement des classes s'effectue en respectant un modèle de délégation de la responsabilité du chargement. Chaque classloader doit déléguer le chargement de la classe à son classloader père : si ce dernier ne peut mener à bien l'opération alors c'est le classloader lui-même qui tente le chargement.
La méthode loadClass() de la classe ClassLoader exécute par défaut les traitements suivants :
C'est pour cette raison qu'il n'est pas recommandé lors de la création d'un classloader de redéfinir la méthode loadClass() mais de redéfinir la méthode findClass().
La JVM recherche et charge les classes requises dans un ordre bien précis grâce à la délégation des classloaders :
Les classes de bootstrap et d'extension n'ont pas besoin d'être précisées explicitement : elles sont trouvées automatiquement. Les autres classes doivent être précisées en utilisant le classpath.
Les classes utilitaires contenues dans le fichier tools.jar doivent être ajoutées explicitement dans le classpath pour pouvoir être utilisées.
Les classes de bootstrap sont les classes fournies avec la plate-forme Java. Elles sont principalement dans le fichier rt.jar mais aussi dans quelques fichiers .jar stockés dans le répertoire lib du JRE. L'ensemble des classes de bootstrap est précisé dans la propriété sun.boot.class.path de la JVM.
Même si cela n'est pas recommandé, il est possible de modifier la propriété sun.boot.class.path en utilisant l'option non standard -Xbootclasspath pour définir sa valeur ou ajouter des éléments en début ou en fin de liste.
Le support des classes d'extension a été ajouté dans Java 1.2. Ces bibliothèques permettent d'enrichir les API de base de Java : il faut donc utiliser ce mécanisme de façon judicieuse.
Les classes d'extension sont des extensions de la plate-forme Java qui sont stockées dans le répertoire lib/ext du JRE. Seules les bibliothèques (.jar ou .zip) sont prises en compte. Il n'est pas possible de préciser ou modifier ce chemin. L'ordre de chargement d'une classe contenue dans plusieurs bibliothèques de ce répertoire n'est pas prévisible.
A partir de Java 1.6, il est possible d'utiliser la variable d'environnement java.ext.dirs pour préciser un ou plusieurs répertoires qui permettront le stockage des extensions. Ceci permet d'utiliser ces répertoires par plusieurs JDK sans être obligé de dupliquer les fichiers .jar dans chaque sous-répertoire lib/ext de chaque JRE.
Les classes d'utilisateurs sont écrites en reposant sur les classes de bootstrap et d'extension. Pour les trouver, la JVM utilise le classpath qui contient un ensemble de répertoires, et de bibliothèques contenant des classes sous la forme de fichiers .jar et/ou .zip.
Il faut mettre dans le classpath l'entité (répertoire ou bibliothèque) qui contient la classe pleinement qualifiée à utiliser.
Exemple :
Le séparateur des différents éléments du classpath dépend de la plate-forme d'exécution ( ; sous Windows et : sous Unix).
Le classpath peut être obtenu grâce à la variable d'environnement java.class.path de la JVM.
Le classpath peut être précisé de plusieurs façons :
La JVM demande au classloader de rechercher et charger le bytecode d'une classe uniquement à sa première utilisation.
Le processus de chargement est composé de trois étapes :
La source du flux n'est pas imposée et peut être un fichier .class local, un fichier .class sur le réseau, une archive (jar ou zip), une génération à la volée, ...
L'instance de la classe Class créée permet une interaction entre une application et la représentation interne de la classe : elle permet par exemple d'obtenir des informations sur la classe.
La liaison de la classe comporte trois étapes :
La vérification est la première étape du processus de liaison : elle permet de s'assurer que la classe chargée est conforme aux spécifications et qu'elle ne risque pas de dégrader la machine virtuelle. La vérification consiste donc en une analyse de la structure et des informations de la classe. Par exemple, pour un fichier .class : vérifier qu'il commence par le nombre magique CAFEBABE, la longueur du fichier, la structure des données, ...
Les spécifications de la JVM détaillent une liste d'exceptions et d'erreurs qui doivent être levées lors de cette étape.
La vérification effectue de nombreux contrôles sur le bytecode tels que :
Certains de ces contrôles nécessitent des informations sur les classes parentes ou sur d'autres classes utilisées qui seront alors chargées mais pas initialisées.
Tous ces contrôles peuvent paraître redondants avec ceux effectués par le compilateur lors de la génération du bytecode mais en fait, il est tout à fait possible que le bytecode ait été altéré, généré à la volée ou que le compilateur présente un ou plusieurs bugs.
Un mécanisme, déjà utilisé depuis longtemps par Java ME, permet d'ajouter des informations de prévérification lors de la compilation. Ainsi l'étape de validation du bytecode est plus rapide à s'exécuter. Depuis la version 6 de Java, le compilateur Java inclut une étape de prévérification qui ajoute des informations dans le fichier.class (StackMap et StackMapTable).
Durant l'étape de préparation, la machine virtuelle alloue la mémoire requise par chaque champs et initialise leurs valeurs avec la valeur par défaut de leur type respectif.
|
int |
0 |
|
long |
0l |
|
short |
0 |
|
char |
'\u0000' |
|
byte |
(byte) 0 |
|
float |
0.0f |
|
double |
0.0d |
|
object |
null |
|
boolean (int) |
false (0) |
Cette étape n'exécute aucun code Java : les valeurs de chaque champ ne sont déterminées que lors de la phase d'initialisation.
Remarque : la machine virtuelle ne définit pas le type booléen. Elle utilise le type int pour sa représentation interne et initialise donc sa valeur à 0 qui correspond à false.
L'étape de résolution permet de rechercher les classes, les interfaces et les membres possédant une référence symbolique dans le constant pool. La résolution permet de remplacer ces références symboliques par des références concrètes.
Ce processus a pour rôle d'initialiser les variables de classe avec leurs valeurs initiales telles que définies dans le code source. La valeur initiale peut être définie de deux façons :
| Exemple : |
public class MaClasse {
static List maListe1 = new ArrayList() ;
static List maListe2 = null;
static {
maListe2 = new ArrayList();
}
}
Ces traitements d'initialisation sont regroupés par le compilateur dans une méthode nommée <clinit (class initialization method). Ils ne concernent que l'exécution de code Java : l'initialisation à l'aide de constantes n'est pas reprise dans cette méthode.
Cette méthode ne peut être invoquée que par la machine virtuelle. Les traitements d'initialisation contenus dans la méthode se font dans l'ordre du code source.
L'initialisation d'une classe implique au préalable l'initialisation de sa classe mère si cela n'a pas déjà été fait et ainsi de suite jusqu'à la classe Object : ainsi toutes les classes mères sont initialisées avant la classe elle-même.
Une classe n'a pas obligatoirement de méthode <clinit() : si la classe ne contient aucune variable de classe ou que toutes ses variables sont déclarées finales avec une valeur constante, elle ne possédera pas de méthode <clinit()
Les spécifications de la JVM imposent que l'initialisation d'une classe intervienne à sa première utilisation active :
L'utilisation d'un classloader implique la mise en oeuvre de la police de sécurité qui lui est associée.
Le simple fait d'utiliser une classe provoque son chargement à sa première utilisation mais il est possible de demander explicitement le chargement d'une classe en invoquant la méthode loadClass() du classloader d'un objet.
Sans police de sécurité, toutes les classes sont considérées comme sûres par défaut.
Même avec une police de sécurité, les classes du bootstrap sont toujours considérées comme sûres.
La police de sécurité repose sur la configuration de la police de sécurité globale et celle de l'application. Par défaut dans la police de sécurité globale, les classes d'extension sont toujours sûres et les autres classes possèdent quelques restrictions.
Le contrôle sur le chargement d'une classe permet notamment de mettre en oeuvre certaines techniques avancées telles que la modification du bytecode, son instrumentation, son cryptage, ...
Les classloaders étant responsables du chargement d'une classe et comme un ClassLoader est une classe, il existe un classloader particulier, le classloader de bootstrap, qui est implémenté en code natif et qui charge les classes de base de Java dont la classe ClassLoader.
Un autre classloader est dédié au chargement des classes d'extensions (celles des bibliothèques stockées dans le sous-répertoire lib/ext du JRE ou à partir de Java 6 celles définies par la propriété java.ext.dirs qui par défaut pointe sur le sous-répertoire lib/ext du JRE).
Le troisième classloader créé automatiquement est celui qui permet de charger les autres classes en particulier celles définies dans le classpath : il se nomme classloader d'application. Il permet le chargement des classes définies dans la propriété java.class.path qui par défaut correspond à la variable d'environnement système CLASSPATH.
Les classloaders ont une organisation hiérarchique permettant la mise en oeuvre d'un mécanisme de délégation du chargement d'une classe : un classloader demande toujours à son classloader père d'essayer de charger la classe.
Le mécanisme de délégation permet de s'assurer qu'une classe sera chargée par le classloader qui lui est dédié :
Une classe est associée au classloader qui l'a chargée. Une fois une classe chargée, celle-ci est identifiée par son nom et son classloader. Ainsi, deux classes de même nom chargées par deux classloaders différents sont considérées comme différentes par la JVM.
Si une classe C1 utilise une classe C2 qui n'est pas encore chargée, alors le classloader par défaut pour charger C2 sera celui de C1. Ainsi une classe de bootstrap ne peut pas utiliser une classe du classpath sauf si c'est le classloader system ou un classloader dédié qui est utilisé.
Un thread est associé à un classloader : pour obtenir une référence sur ce classloader, il faut utiliser la méthode getContextClassLoader(). C'est en général le classloader de la classe qui a démarré le thread. Il est parfois nécessaire d'utiliser le classloader du thread notamment avec les servlets qui sont généralement chargées par un classloader dédié du conteneur web. Ce classloader ne permet généralement que de charger des classes contenues dans l'application web, ce qui lui interdit le chargement des classes du classpath.
Dans une JVM, il existe deux classloaders par défaut :
Il est aussi possible de définir son propre classloader.
Le classloader possède une méthode loadClass() qui permet de charger une classe à partir de son nom de fichier binaire. Le nom de binaire de la classe correspond au nom pleinement qualifié de la classe incluant le signe $ et l'incrémentation pour les classes anonymes.
Exemple :
java.lang.String
fr.jmdoudoux.dej.monapp.MonApp
fr.jmdoudoux.dej.monapp.MonApp$1
La méthode loadClass() lève une exception de type ClassNotFoundException si la classe n'est pas trouvée.
Il y a plusieurs façons pour forcer le chargement d'une classe par un classloader :
| Exemple : |
package fr.jmdoudoux.dej.classloader;
public class TestClassLoaderla {
public static void main(String[] args) {
try {
System.out.println(
TestClassLoader1a.class.getClassLoader().loadClass("java.lang.Number"));
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
| Exemple : |
package fr.jmdoudoux.dej.classloader;
public class TestClassLoader1b {
public static void main(String[] args) {
try {
System.out.println(Class.forName("java.lang.Number"));
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
| Exemple : |
package fr.jmdoudoux.dej.classloader;
public class TestClassLoader1c {
public static void main(String[] args) {
System.out.println(Number.class);
}
}
Chaque objet chargé par un classloader conserve une référence sur ce dernier : la méthode getClassLoader() de la classe Class permet d'obtenir cette référence.
Seule la JVM peut utiliser le classloader de bootstrap : ainsi l'appel de la méthode getClassLoader() d'une classe chargée par le classloader de bootstrap renvoie null.
La classe ClassLoader propose la méthode statique getSystemClassLoader() pour obtenir le classloader système. Sauf création d'un classloader dédié, c'est ce classloader qui charge les classes utilisateurs.
| Exemple : |
package fr.jmdoudoux.dej.classloader;
public class TestClassLoader4 {
public static void main(String[] args) {
System.out.println(String.class.getClassLoader());
System.out.println(ClassLoader.getSystemClassLoader());
System.out.println(TestClassLoader4.class.getClassLoader());
}
}
| Résultat : |
null
sun.misc.Launcher$AppClassLoader@11b86e7
sun.misc.Launcher$AppClassLoader@11b86e7La classe URLClassLoader est un classloader qui charge des classes à partir d'une ou plusieurs URL fournies en paramètre. Ces urls peuvent correspondre à des répertoires ou à des fichiers jar.
| Exemple : le fichier c:\java\test.jar contient la classe fr.jmdoudoux.dej.MaClasse |
package fr.jmdoudoux.dej.classloader;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLClassLoader;
public class TestClassLoader5 {
public static void main(String[] args) {
try {
URLClassLoader loader = new URLClassLoader(new URL[] {
new URL("file:///C:/java/test.jar") });
Class<?> maClasseClass = loader.loadClass("fr.jmdoudoux.dej.MaClasse");
System.out.println(maClasseClass);
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
Les classloaders assurent qu'une même classe n'est chargée qu'une seule fois par une même hiérarchie de classloaders.
| Exemple : |
package fr.jmdoudoux.dej.classloader;
public class TestClassLoader3 {
public static void main(String[] args) {
try {
boolean resultat = (String.class == Class.forName("java.lang.String"));
System.out.println("comparaison = "+resultat);
} catch (Exception e) {
e.printStackTrace();
}
}
}
| Résultat : |
comparaison = trueLe classloader permet aussi de charger des ressources grâce à plusieurs méthodes :
|
Méthode |
Rôle |
|
URL getResource(String name) |
Renvoie l'url d'une ressource trouvée par le classloader |
|
InputStream getResourceAsStream(String name) |
Renvoie un flux pour lire la ressource |
|
URL getSystemResource(String name) |
Méthode statique utilisant le classloader système qui renvoie l'url d'une ressource trouvée |
|
InputStream getSystemResourceAsStream(String name) |
Méthode statique utilisant le classloader système qui renvoie un flux pour lire la ressource |
Le chargement des ressources en utilisant le classloader est obligatoire par exemple pour charger une ressource incluse dans un fichier .jar.
L'option -verbose:class de la JVM permet de demander l'affichage d'informations sur le chargement des classes.
| Résultat : |
...
[Loaded java.lang.StrictMath from shared objects file]
[Loaded sun.security.provider.NativePRNG from shared objects file]
[Loaded sun.misc.CharacterDecoder from shared objects file]
[Loaded sun.misc.BASE64Decoder from shared objects file]
[Loaded sun.security.util.SignatureFileVerifier from shared objects file]
[Loaded fr.jmdoudoux.dej.MaClasse from file:/C:/java/test.jar]
...Cette option peut permettre de déterminer à partir de quelle source une classe est chargée.
Il existe une hiérarchie dans les classloaders ce qui permet à un classloader de déléguer le chargement d'une classe à son classloader père. La méthode getParent() de la classe ClassLoader permet de connaître le classloader père. Le classloader de bootstrap ne possède pas de père.
Cette délégation permet notamment de s'assurer que les classes de bootstrap sont chargées par la classeloader de bootstrap. La délégation est effectuée dans la méthode loadClass() qui devrait toujours demander au classloader père de charger la classe.
| Exemple : |
package fr.jmdoudoux.dej.classloader;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLClassLoader;
public class TestClassLoader6 {
public static void main(String[] args) {
URLClassLoader loader;
try {
loader = new URLClassLoader(new URL[] {
new URL("file:///C:/Program Files/Java/jre1.6.0_03/lib/rt.jar") });
Class<?> stringClass = loader.loadClass("java.lang.String");
System.out.println(stringClass.getClassLoader());
System.out.println(String.class.getClassLoader());
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
| Résultat : |
null
nullBien que le chargement de la classe String soit demandé par une instance de la classe URLClassLoader, la classe est chargée par le classloader de bootstrap. Comme les deux demandes de chargement sont réalisées par le même classloader, les deux classes sont identiques.
Une classe est liée à son classloader : une même classe chargée par deux classloaders sera chargée deux fois (il y aura deux instances de la classe Class correspondante)
| Exemple : |
package fr.jmdoudoux.dej.classloader;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLClassLoader;
public class TestClassLoader7 {
public static void main(String[] args) {
try {
URLClassLoader loader1 = new URLClassLoader(new URL[] {
new URL("file:///C:/java/test.jar") });
Class<?> maClasseClass1 = loader1.loadClass("fr.jmdoudoux.dej.MaClasse");
System.out.println(maClasseClass1);
URLClassLoader loader2 = new URLClassLoader(
new URL[] { new URL("file:///C:/java/test.jar") });
Class<?> maClasseClass2 = loader2.loadClass("fr.jmdoudoux.dej.MaClasse");
System.out.println(maClasseClass2);
System.out.println(maClasseClass1 == maClasseClass2);
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
| Résultat : |
class fr.jmdoudoux.dej.MaClasse
class fr.jmdoudoux.dej.MaClasse
false
L'utilisation d'un classloader dédié peut avoir plusieurs utilités par exemple :
Les conteneurs web et les serveurs d'applications sont de bons exemples d'applications qui utilisent des classloaders personnalisés. Généralement, chaque application déployée possède son propre classloader ce qui permet une meilleure isolation des applications exécutées dans la JVM.
Ceci est vrai parce qu'une classe chargée dans la JVM est identifiée par son nom et son classloader. Ceci permet par exemple à un singleton utilisé par plusieurs applications d'être unique par application et non unique dans la JVM puisque chaque application possède son propre classloader.
Ceci permet aussi un rechargement des classes d'une application déployée sans être obligé de relancer la JVM.
L'écriture d'un classloader personnalisé peut permettre de modifier le bytecode : une fois le bytecode chargé le classloader peut le modifier avant de demander son initialisation par la JVM.
Un classloader doit hériter de la classe java.lang.ClassLoader.
La classe ClassLoader possède plusieurs méthodes :
|
Méthode |
Rôle |
|
loadClass() |
charger une classe en demandant au préalable au classloader père de réaliser l'opération |
|
findClass() |
charger une classe |
|
defineClass() |
Ajouter le bytecode de la classe dans la machine virtuelle |
Lors de la création de son propre classloader, il faut redéfinir la méthode findClass() plutôt que la méthode loadClass() pour respecter le mécanisme de délégation de chargement de classes des classloaders.
La méthode findClass() ne doit donc être invoquée que si la classe n'a pas pu être chargée par un des classloaders pères.
Les données binaires issues de la lecture du fichier et éventuellement enrichies sont passées en paramètres de la méthode defineClass().
Pour utiliser un classloader personnalisé, il faut explicitement demander son utilisation :
Comme par défaut le mécanisme de délégation du chargement d'une classe demande au classloader parent de tenter de charger la classe, il faut être sûr que la classe à charger ne se trouve pas dans un classpath particulier (bootstrap classpath, extension classpath, system classpath). Sinon la classe ne sera pas chargée par le classloader personnalisé mais par un de ses classloaders pères.
Cette fonctionnalité est utilisée par les conteneurs web qui encouragent l'utilisation du sous-répertoire WEB-INF/classes plutôt que de mettre les bibliothèques dans le classpath.
Le bytecode est un langage intermédiaire entre le code source et le code machine qui permet de rendre l'exécution d'applications Java multiplate-forme puisque le bytecode est un langage intermédiaire indépendant de tout système d'exploitation.
La JVM fournit un environnement d'exécution pour le bytecode en le convertissant en code machine du système d'exploitation utilisé.
Le bytecode peut être modifié avant son exécution par un classloader dédié. Cette modification ou génération de bytecode est par exemple utilisée par :
La génération directe de bytecode est plus efficace que la génération de code source puisqu'elle évite l'étape de compilation mais elle est aussi de fait plus compliquée.
Le bytecode est défini dans les spécifications de la machine virtuelle Java.
Le bytecode est composé de mnémoniques qui réalisent des opérations sur éventuellement un ou plusieurs opérandes. A chaque mnémonique correspond un opcode.
Le compilateur transforme le code source Java en fichiers .class contenant entre autres le bytecode.
Lors de la compilation du code source en bytecode, le compilateur effectue de nombreuses vérifications notamment sur la syntaxe du code source pour garantir que le bytecode produit est valide et qu'il ne risque pas de nuire à la JVM qui va l'exécuter.
Lors du chargement d'un fichier .class, le classloader effectue des vérifications sur le contenu du fichier afin de s'assurer qu'il ne soit pas en mesure de mettre à mal l'intégrité de la machine virtuelle :
D'autres langages peuvent être utilisés avec un compilateur dédié pour créer du bytecode par exemple :
Lorsque le compilateur crée un fichier .class, il incorpore la version du bytecode qui est une représentation numérique de la valeur fournir avec les options -target ou --release. Si elles ne sont pas précisées, c'est la version du JDK qui est utilisée par défaut.
Les versions de bytecode sont calculées avec une simple formule : 44 + la version de Java précisée avec -target ou --release.
|
Version du JDK |
Version du bytecode |
Version du JDK |
Version du bytecode |
Version du JDK |
Version du bytecode |
|
Java 1.0 |
45.0 |
Java 10 |
54.0 |
Java 20 |
64.0 |
|
Java 1.1 |
45.3 |
Java 11 |
55.0 |
Java 21 |
65.0 |
|
Java 1.2 |
46.0 |
Java 12 |
56.0 |
Java 22 |
66.0 |
|
Java 1.3 |
47.0 |
Java 13 |
57.0 |
||
|
Java 1.4 |
48.0 |
Java 14 |
58.0 |
||
|
Java 5 |
49.0 |
Java 15 |
59.0 |
||
|
Java 6 |
50.0 |
Java 16 |
60.0 |
||
|
Java 7 |
51.0 |
Java 17 |
61.0 |
||
|
Java 8 |
52.0 |
Java 18 |
62.0 |
||
|
Java 9 |
53.0 |
Java 19 |
63.0 |
Lorsque la JVM charge une classe, elle vérifie si elle supporte la version du bytecode et si ce n'est pas le cas, elle lève une exception de type Error.
Jusqu'à Java 7, une exception de type UnsupportedClassVersionError est levée par la JVM si la version du bytecode est incompatible avec la version de la JVM utilisée
| Résultat : |
C:\java>java -version
openjdk version "1.7.0_75"
OpenJDK Runtime Environment (build 1.7.0_75-b13)
OpenJDK Client VM (build 24.75-b04, mixed mode)
C:\java>java Hello
Exception in thread "main" java.lang.UnsupportedClassVersionError: Hello : Unsupported
major.minor version 63.0
A partir de Java 8, le message de l'exception de type UnsupportedClassVersionError est plus précis.
| Résultat : |
C:\java>java -version
openjdk version "1.8.0_252"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_252-b09)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.252-b09, mixed mode)
C:\java>java Hello
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.UnsupportedClassVersionError: Hello has been
compiled by a more recent version of the Java Runtime (class file version 63.0), this version
of the Java Runtime only recognizes class file versions up to 52.0
A partir de Java 9, une LinkageError est levée, chaînée avec l'exception de type UnsupportedClassVersionError. La stacktracce n'est plus affichée car elle n'apportait rien d'utile.
| Résultat : |
C:\java>java -version
java version "9.0.1"
Java(TM) SE Runtime Environment (build 9.0.1+11)
Java HotSpot(TM) 64-Bit Server VM (build 9.0.1+11, mixed mode)
C:\java>java Hello
Erreur : LinkageError lors du chargement de la classe principale Hello
java.lang.UnsupportedClassVersionError: Hello has been compiled by a more recent
version of the Java Runtime (class file version 63.0), this version of the Java Runtime
only recognizes class file versions up to 53.0
Jclasslib est un outil graphique gratuit qui permet de visualiser le bytecode contenu dans un fichier .class.
Il peut être téléchargé à l'url https://github.com/ingokegel/jclasslib
L'installation se fait sous Windows avec l'aide d'un assistant en exécutant le fichier jclasslib_win64_6_0_4.exe. Il suffit d'exécuter l'outil et d'utiliser l'option « File/Open Class File » en sélectionnant le fichier .class.
| Exemple : |
public class MaClasse {
public static void main(String[] args) {
System.out.println("Bonjour");
}
}
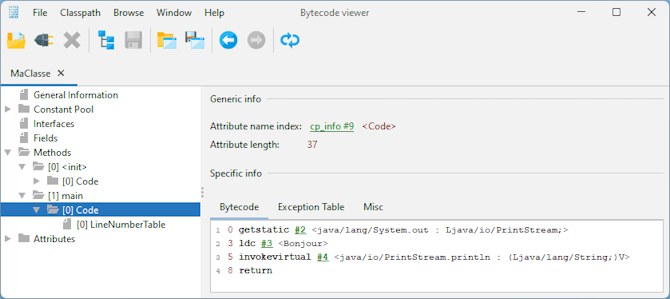
La partie de gauche affiche une vue hiérarchique de la structure du fichier. La partie de droite affiche le contenu de l'élément sélectionné dans la partie de gauche
A partir de la version 6.0, de nombreux aspects des fichiers .class peuvent être modifiés dans l'interface utilisateur.
La JVM possède un ensemble d'instructions qui sont utilisées pour définir des traitements. Le code source représentant la logique des traitements est compilé pour générer un fichier binaire .class.
Les instructions de la JVM sont des opérations basiques qui combinées permettent de réaliser les traitements.
Une instruction est composée d'un code opération (opcode) suivi d'aucun, un ou plusieurs opérandes qui représentent les paramètres de l'instruction.
Chaque code opération correspond à une valeur stockée sur un octet.
| Exemple : |
package fr.jmdoudoux.dej;
public class ClasseDeTest {
public static void main(String[] args) {
for (int i =1; i <=10; i++) {}
}
}
| Résultat : utilisation de l'outil de desassemblage javap |
C:\Documents and Settings\jmd\workspace\Tests\bin\com\jmdoudoux\test>javap -c Cl
asseDeTest
Compiled from "ClasseDeTest.java"
public class fr.jmdoudoux.dej.ClasseDeTest extends java.lang.Object{
public fr.jmdoudoux.dej.ClasseDeTest();
Code:
0: aload_0
1: invokespecial #8; //Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: iconst_1
1: istore_1
2: goto 8
5: iinc 1, 1
8: iload_1
9: bipush 10
11: if_icmple 5
14: return
}La plupart des instructions sont très basiques. Par exemple, les instructions de l'exemple précédent sont :
iconst_1 : définit une constante entière ayant pour valeur 1
istore_1 : copie la valeur en haut de la pile dans la variable dont l'index est précisé
Le format des fichiers .class est décrit dans les spécifications de la JVM.
Un fichier .class est un fichier binaire qui contient :
 |
|
La suite de cette section sera développée dans une version future de ce document
|
Le bytecode est indépendant de toute plate-forme : une fois le code source compilé en bytecode, celui-ci peut être exécuté tel quel sur toute plate-forme disposant d'une JVM sous réserve qu'aucun appel à du code natif ne soit fait avec l'API JNI.
La JVM se charge alors d'interpréter le bytecode lors de son exécution pour le transformer en instructions compréhensibles par le processeur de la plate-forme. Ce processus qui assure l'indépendance du bytecode vis-à-vis de la plate-forme à aussi l'inconvénient d'être lent car il nécessite une interprétation du bytecode et que cette interprétation doit avoir lieu à chaque appel d'une méthode même si cette méthode doit être invoquée plusieurs fois.
L'idée d'un compilateur JIT est de compiler en code natif le bytecode d'une méthode, de stocker le résultat de cette compilation et d'exécuter ce code compilé chaque fois que la méthode est invoquée.
Le but d'un compilateur JIT (Just In Time) est donc d'améliorer les performances de l'exécution du bytecode.
Ce compilateur est intégré à la JVM pour que son action n'intervienne qu'à l'exécution et préserve la portabilité du bytecode. Le compilateur JIT modifie le rôle de la machine virtuelle qui interprète le bytecode en compilant ce dernier à la volée en code natif. Ceci améliore généralement les performances puisqu'une fois le bytecode compilé en natif il peut être exécuté directement par le système.
Les méthodes ne sont compilées par le compilateur JIT qu'au moment de leur exécution. Une fois celle-ci compilée, c'est la version compilée qui sera exécutée au lieu de la version interprétée. L'intérêt du compilateur JIT est donc d'autant plus grand que la méthode est invoquée plus souvent.
Un compilateur JIT est inclus dans la JVM hotspot depuis la version 1.2 de Java.
La performance ajoutée par l'utilisation d'un compilateur JIT est induite par plusieurs faits :
Le temps nécessaire au compilateur JIT pour compiler le code peut être pénalisant d'autant que le temps nécessaire au compilateur peut augmenter avec la quantité d'optimisation réalisée par le compilateur.
La machine virtuelle HotSpot peut fonctionner selon deux modes. Dans le mode client, c'est la réduction du temps de compilation qui est privilégiée au détriment des optimisations. Dans le mode serveur, c'est l'optimisation qui est privilégiée ce qui allonge le temps de compilation.
La JVM Hotpsot possède des options standard et des options non standard qui peuvent être dépendantes de la plate-forme d'exécution. Les options standards sont décrites dans la section dédiée à la commande java.
Les paramètres non standard sont préfixés par -X : il n'y a aucune garantie sur leur support dans les différentes versions de la JVM. L'option -X permet d'obtenir un résumé des options non standard supportées par la JVM.
| Résultat : |
C:\>java -version
java version "1.6.0_11"
Java(TM) SE Runtime Environment (build 1.6.0_11-b03)
Java HotSpot(TM) Client VM (build 11.0-b16, mixed mode, sharing)
C:\>java -X
-Xmixed mixed mode execution (default)
-Xint interpreted mode execution only
-Xbootclasspath:<directories and zip/jar files separated by ;>
set search path for bootstrap classes and resources
-Xbootclasspath/a:<directories and zip/jar files separated by ;>
append to end of bootstrap class path
-Xbootclasspath/p:<directories and zip/jar files separated by ;>
prepend in front of bootstrap class path
-Xnoclassgc disable class garbage collection
-Xincgc enable incremental garbage collection
-Xloggc:<file> log GC status to a file with time stamps
-Xbatch disable background compilation
-Xms<size> set initial Java heap size
-Xmx<size> set maximum Java heap size
-Xss<size> set java thread stack size
-Xprof output cpu profiling data
-Xfuture enable strictest checks, anticipating future default
-Xrs reduce use of OS signals by Java/VM (see documentation)
-Xcheck:jni perform additional checks for JNI functions
-Xshare:off do not attempt to use shared class data
-Xshare:auto use shared class data if possible (default)
-Xshare:on require using shared class data, otherwise fail.
The -X options are non-standard and subject to change without notice.Les principales options non standard sont :
|
Option |
Rôle |
|
-Xint |
Désactiver le compilateur JIT : dans ce cas tout le bytecode est exécuté en mode interprété uniquement. |
|
-Xbatch |
Désactiver la compilation en tâche de fond |
|
-Xbootclasspath:bootclasspath |
Définir les répertoires, les jar ou les archives zip qui composent les classes de bootstrap. Chaque élément est séparé par un point virgule. |
|
-Xbootclasspath/a:path |
Ajouter des répertoires, des jar ou des archives zip aux classes de bootstrap |
|
-Xcheck:jni |
Effectuer des contrôles poussés sur les paramètres utilisés lors d'appels à des méthodes natives avec JNI. Si un problème est détecté lors de ces contrôles, alors la machine virtuelle est arrêtée avec une erreur fatale. L'activation de cette option dégrade les performances mais renforce la stabilité de la JVM lors des appels à des méthodes natives. |
|
-Xnoclassgc |
Désactiver la récupération de la mémoire par le ramasse-miettes des classes chargées mais inutilisées. Ceci peut légèrement améliorer les performances mais provoquer un manque de mémoire. |
|
-Xincgc |
Active les collectes incrémentales pour le ramasse-miettes. Ceci permet de réduire les longs temps de pauses nécessaires au ramasse-miettes en réalisant une partie de son activité de façon concomitante avec l'exécution de l'application. |
|
-Xloggc:file |
Active les traces d'exécution du ramasse-miettes dans un fichier de log fourni en paramètre. Il est recommandé d'utiliser un fichier sur le système de fichiers local pour éviter des problèmes de latences réseaux. Cette option est prioritaire sur l'option -verbose:gc si les deux sont fournies à la JVM |
|
-Xmsn |
Permet de préciser la taille initiale du tas. La valeur par défaut dépend du système d'exploitation. |
|
-Xmxn |
Permet de préciser la taille maximale du tas. La valeur par défaut dépend du système d'exploitation. |
|
-Xprof |
Activer l'affichage sur la console de traces de profiling. A défaut de mieux, cette option peut être utilisée dans un environnement de développement mais ne doit pas être utilisée en production car elle dégrade les performances |
|
-Xssn |
Permet de définir la taille de la pile des threads |
Tous les paramètres qui sont préfixés par -XX sont spécifiques à la JVM HotSpot et parfois dépendants de la plate-forme d'exécution.
La syntaxe de ces options dépend de leur type :
|
options booléennes |
la syntaxe pour activer l'option est -XX:+<option> et -XX:-<option> pour la désactiver |
|
options numériques |
-XX:<option>=<valeur>. Si la valeur représente une quantité de données, il est possible de préfixer la valeur avec une lettre qui représente l'unité utilisée ('k' ou 'K' pour kilo bytes, 'm' ou 'M' pour mega bytes, et 'g' ou 'G' pour giga bytes) |
|
options littérales |
-XX:<option>=<valeur> |
La JVM possède selon sa version de nombreuses options -XX dont voici les principales :
|
Option |
Type |
Rôle |
|
-XX:DisableExplicitGC |
booléen |
Empêcher l'invocation explicite de la méthode System.gc() |
|
-XX:ScavengeBeforeFullGC |
booléen |
Effectuer une récupération de la mémoire de la young generation avant d'effectuer un full garbage collector |
|
-XX:UseConcMarkSweepGC |
booléen |
Utiliser l'algorithme concurrent mark and sweep pour la récupération de la mémoire de la tenured generation |
|
-XX:UseGCOverheadLimit |
booléen |
Activer ou non la levée d'une exception de type OutOfMemoryError si la VM passe 98% de son temps dans l'activité du ramasse-miettes pour ne récupérer qu'une faible quantité de mémoire. Le but étant d'éviter des traitements longs qui sont quasi inutiles (Depuis Java 6) |
|
-XX:UseParallelGC |
booléen |
Demander l'utilisation de l'algorithme parallel collector par le ramasse-miettes (Depuis Java 1.4.1) |
|
-XX:UseParallelOldGC |
booléen |
Demander l'utilisation de l'algorithme parallel compacting collector par le ramasse-miettes (Depuis Java 5 update 6) |
|
-XX:UseSerialGC |
booléen |
Utiliser l'algorithme serial pour la récupération de la mémoire de la tenured generation (depuis Java 5.0) |
|
-XX:UseThreadPriorities |
booléen |
Demander l'utilisation des priorités des threads natifs |
|
-XX:MaxHeapFreeRatio |
numérique |
Préciser le pourcentage maximum de mémoire libre du tas après une récupération de mémoire afin de provoquer une réduction au besoin de la taille du tas |
|
-XX:MaxNewSize |
numérique |
Préciser la taille maximale de la young generation (depuis Java 1.4) |
|
-XX:MaxPermSize |
numérique |
Préciser la taille maximale de la permanent generation. La taille par défaut dépend de la plate-forme |
|
-XX:MinHeapFreeRatio |
numérique |
Préciser le pourcentage minimum de mémoire libre du tas après une récupération de mémoire afin de provoquer une extension de la taille du tas |
|
-XX:NewRatio |
numérique |
Préciser le ratio de la taille des deux générations (old et tenured). Les valeurs par défaut dépendent de la plate-forme d'exécution |
|
-XX:NewSize |
numérique |
Préciser la taille de la young generation |
|
-XX:ReservedCodeCacheSize |
numérique |
Préciser la taille de la zone de mémoire code cache |
|
-XX:SurvivorRatio |
numérique |
Préciser le ratio de la taille des espaces eden et des deux survivors de la young generation |
|
-XX:ThreadStackSize |
numérique |
Préciser la taille en kilo octets de la pile d'un thread. La valeur 0 indique d'utiliser la valeur par défaut |
|
-XX:UseFastAccessorMethods |
booléen |
Demander l'utilisation de la version optimisée des getters |
|
-XX:StringCache |
booléen |
Activer la mise en cache des chaînes de caractères. |
|
-XX:CITime |
booléen |
Afficher des informations sur le temps d'exécution du compilateur JIT (depuis Java 1.4) |
|
-XX:ErrorFile |
littéral |
Préciser le fichier qui va contenir la log en cas d'erreur fatale. (depuis Java 6) |
|
-XX:HeapDumpPath |
littéral |
Préciser le chemin ou le nom du fichier qui va contenir le dump du tas (depuis Java 1.4.2, Java 5 update 7) |
|
-XX:HeapDumpOnOutOfMemoryError |
booléen |
Demander la génération d'un dump au format binaire HPROF dans un fichier du répertoire courant dans le cas où une exception de type OutOfMemoryError est levée. Le nom de ce fichier est de la forme java_pidxxxx.hprof où xxxx est le pid de la JVM. (depuis Java 1.4.2 update 12 et Java 5.0 update 7) |
|
-XX:OnError |
littéral |
Demander l'exécution d'un script ou d'une ou plusieurs commandes séparées par un point virgule lorsqu'une erreur fatale survient. (depuis Java 1.4.2 update 9). La séquence %p peut être utilisée pour indiquer le process ID (pid) Exemple : java -XX:OnError="cat hs_err_pid%p.log|mail jmd@test.fr" MomApp |
|
-XX:OnOutOfMemoryError |
littéral |
Demander l'exécution d'un script ou d'une ou plusieurs commandes séparées par un point virgule lorsqu'une exception de type OutOfMemomryError est levée. (depuis Java 1.4.2 update 12) |
|
-XX:PrintClassHistogram |
booléen |
Afficher un histogramme des instances de classes du tas lors de l'appui sur Ctrl-Break (Depuis Java 1.4.2) |
|
-XX:PrintConcurrentLocks |
booléen |
Afficher une liste des verrous d'accès concurrents (locks) de chaque thread lors de l'appui sur Ctrl-Break (Depuis Java 6) |
|
-XX:PrintCommandLineFlags |
booléen |
Afficher les options fournies à la JVM par la ligne de commande (depuis Java 5) |
|
-XX:PrintCompilation |
booléen |
Activer l'affichage de messages d'information lors de la compilation du bytecode d'une méthode. |
|
-XX:PrintGC |
booléen |
Activer l'affichage de messages d'informations lors de l'exécution du ramasse-miettes |
|
-XX:PrintGCDetails |
booléen |
Activer l'affichage de messages d'informations détaillées lors de l'exécution du ramasse-miettes (depuis Java 1.4) |
|
-XX:PrintGCTimeStamps |
booléen |
Afficher un timestamp à chaque exécution du ramasse-miettes (depuis Java 1.4) |
|
-XX:PrintTenuringDistribution |
booléen |
Afficher une liste de la taille des objets ayant survécus aux dernières exécutions du ramasse-miettes dans la young generation (Depuis Java 6 pour le parallel collector) |
|
-XX:TraceClassLoading |
booléen |
Activer l'affichage de messages lors du chargement des classes |
|
-XX:TraceClassUnloading |
booléen |
Activer l'affichage de messages lors du déchargement des classes |
|
-XX:ShowMessageBoxOnError |
booléen |
Afficher une demande à l'utilisateur s'il souhaite lancer le débogueur natif (exemple Visual Studio sous Windows) si la JVM rencontre une erreur fatale. |
Depuis Java 6, il est possible de modifier dynamiquement certaines de ces options en utilisant le MBean HotSpotDiagnostic exposé par la JVM.
Le contenu de ce chapitre concerne la version 1.6 de la JVM HotSpot.
| Résultat : |
C:\Documents and Settings\T30>java -version
java version "1.6.0_02"
Java(TM) SE Runtime Environment (build 1.6.0_02-b06)
Java HotSpot(TM) Client VM (build 1.6.0_02-b06, mixed mode, sharing)L'option -X permet d'obtenir de l'aide sur les paramètres de la JVM dont la plupart concerne la gestion de la mémoire.
| Résultat : |
C:\>java -X
-Xmixed mixed mode execution (default)
-Xint interpreted mode execution only
-Xbootclasspath:<directories and zip/jar files separated by ;>
set search path for bootstrap classes and resources
-Xbootclasspath/a:<directories and zip/jar files separated by ;>
append to end of bootstrap class path
-Xbootclasspath/p:<directories and zip/jar files separated by ;>
prepend in front of bootstrap class path
-Xnoclassgc disable class garbage collection
-Xincgc enable incremental garbage collection
-Xloggc:<file> log GC status to a file with time stamps
-Xbatch disable background compilation
-Xms<size> set initial Java heap size
-Xmx<size> set maximum Java heap size
-Xss<size> set java thread stack size
-Xprof output cpu profiling data
-Xfuture enable strictest checks, anticipating future default
-Xrs reduce use of OS signals by Java/VM (see documentation)
-Xcheck:jni perform additional checks for JNI functions
-Xshare:off do not attempt to use shared class data
-Xshare:auto use shared class data if possible (default)
-Xshare:on require using shared class data, otherwise fail.
The -X options are non-standard and subject to change without notice.L'option -Xms permet de préciser la taille initiale du tas (heap) de la JVM
| Résultat : |
-Xms256mGénéralement la valeur par défaut de ce paramètre est insuffisante surtout pour des applications serveur.
L'option -Xmx permet de préciser la taille maximale du tas (heap) de la JVM.
| Résultat : |
-Xmx512mLa quantité de mémoire peut être précisée avec plusieurs unités :
La JVM étend automatiquement la taille du tas de la taille précisée par Xms jusqu'à Xmx lorsque le pourcentage de l'espace libre devient inférieur à la valeur précisée par le paramètre -XX:MinHeapFreeRatio. Le paramètre -XX:MaxHeapFreeRatio est équivalent mais réduit la taille du tas si le pourcentage d'espace libre est supérieur à celui fourni.
L'option -verbose:gc permet d'afficher des informations sur chaque récupération de mémoire dont chacune sera sur une ligne distincte.
| Résultat : |
[GC 896K->248K(5056K), 0.0057627 secs]
[GC 1144K->343K(5056K), 0.0034792 secs]
[GC 1239K->504K(5056K), 0.0035857 secs]Les valeurs numériques de part et d'autre du signe -> correspondent à la valeur de mémoire occupée avant et après la récupération de mémoire.
Le nombre de secondes indique le temps utilisé par la récupération de mémoire.
Le paramètre -XX:+PrintGCTimesStamps permet d'ajouter en début de ligne un timestamp pour chaque exécution.
| Résultat : |
0.296: [GC 896K->248K(5056K), 0.0057633 secs]
0.439: [GC 1144K->343K(5056K), 0.0033870 secs]
0.548: [GC 1239K->504K(5056K), 0.0035510 secs]L'option -Xnoclassgc permet de désactiver le déchargement d'une classe lorsque plus aucune instance de cette classe n'est présente dans la mémoire de la JVM. Ceci évite d'avoir à recharger la classe.
La machine virtuelle propose des interfaces pour permettre sa connexion avec des outils externes de profiling ou de débogage.
JVMDI est une des couches de l'architecture de débogage de la plate-forme Java.
JVMDI est une API native de bas niveau utilisée par les débogueurs et d'autres outils de programmation pour interagir de manière bidirectionnelle avec la JVM. Elle permet d'inspecter l'état et de contrôler l'exécution des applications dans une JVM.
Les clients JVMDI s'exécutent dans la même machine virtuelle que l'application en cours de débogage et accèdent à JVMDI en utilisant une interface native.
Un client JVMDI peut être notifié d'événements qui surviennent durant l'exécution. JVMDI peut interroger et contrôler l'application en utilisant différentes fonctions, soit en réponse à des événements, soit indépendamment de ceux-ci.
À partir de Java 5.0, JVMDI est dépréciée et est retirée à partir de Java 6.
L'API Java Virtual Machine Profiler Interface (JVMPI) standardise les interactions entre la JVM et un profiler.
C'est une interface bidirectionnelle qui définit
Un agent du profiler est exécuté directement dans la JVM sous une forme native.
Pour exécuter l'agent, la JVM doit être lancée avec le paramètre -XrunProfilerLibrary où ProfilerLibrary est le nom de la bibliothèque native de l'agent.
JVMPI est deprecated à partir de la version 5.0 de Java et est désactivée à partir de la version 6.0 de Java.
L'API JVMPI est remplacée par l'API Java Virtual Machine Tools Interface (JVMTI). Cette API est spécifiée dans la JSR 163 (Java Platform Profiling Architecture)
Cette API est composée d'une partie native (en C/C++) et d'une partie en pure Java. Cette API permet le développement d'outils qui vont interroger l'état de la JVM (outil de profiling, monitoring, débogage, ...). Ces outils sont développés sous la forme d'agents.
L'API Java est contenue dans le package java.lang.instrument.
Les spécifications de la version 1.2 sont consultables à l'url
https://docs.oracle.com/javase/6/docs/platform/jvmti/jvmti.html
Le JDK propose plusieurs exemples de mise en oeuvre de JVMTI dans le sous-répertoire demo/jvmti du répertoire d'installation du JDK.
Java Platform Debugger Architecture (JPDA) est une architecture pour les outils de type débogueur.
Cette architecture repose sur deux API :
Le protocole Java Debug Wire Protocol (JDWP) formalise les échanges entre le débogueur et les traitements en cours de débogage.
Les spécifications de JPDA sont consultables à l'url
https://docs.oracle.com/javase/6/docs/technotes/guides/jpda/index.html
Un exemple de mise en oeuvre de JPDA est proposé dans le sous-répertoire /demo/jpda du répertoire d'installation du JDK.
Il existe plusieurs profilers open source notamment :
Une liste complète des profilers open source est disponible à l'url :
https://java-source.net/open-source/profilers
Il existe aussi plusieurs solutions commerciales notamment JProfiler ou OptimizeIt.
Java 6 propose un mécanisme pour charger dynamiquement des services définis dans un fichier de configuration dédié. Un service est un ensemble d'interfaces et de classes qui fournissent des fonctionnalités particulières.
Le Service Provider Interface (SPI) est un mécanisme qui permet de charger dynamiquement des objets respectant une interface définie. Le JDK propose plusieurs services de type SPI dans ses API, par exemple :
Par convention dans le JDK, certains services sont dans un sous-package spi (exemple : java.text.spi, java.nio.channels.spi, java.nio.charset.spi, ...).
Cette fonctionnalité permet la recherche et le chargement de classes dynamiques au chargement d'un jar. Le service provider est donc un mécanisme simple et pratique pour permettre l'utilisation d'implémentations différentes d'un service.
Un service provider interface (SPI) est une interface ou une classe abstraite qui définit les fonctionnalités du service. Un service provider est une implémentation d'un SPI.
Le mécanisme de SPI permet de mettre en place une certaine extensibilité et modularité dans une application. Ceci peut par exemple permettre la mise en oeuvre d'un mécanisme d'utilisation de plug-in basique.
Il faut définir une interface qui décrit les fonctionnalités proposées par le service.
| Exemple : |
package fr.jmdoudoux.dej.spi;
public interface MonService {
public void executer();
}
Il faut définir une ou plusieurs implémentations de l'interface du service qui doivent obligatoirement avoir un constructeur sans paramètres.
| Exemple : |
package fr.jmdoudoux.dej.spi;
public class MonServiceSimple implements MonService {
public void executer() {
System.out.println("Mon service simple");
}
}
| Exemple : |
package fr.jmdoudoux.dej.spi;
public class MonServiceComplexe implements MonService {
public void executer() {
System.out.println("Mon service complexe");
}
}
Il faut créer un sous-répertoire META-INF/services dans le jar.
Il faut créer un fichier dans le sous-répertoire services qui se nomme du nom pleinement qualifié de l'interface. Ce fichier est le fichier de configuration qui doit contenir le nom pleinement qualifié de chaque implémentation utilisable, chacune étant sur une ligne dédiée. Il est possible de mettre des commentaires en utilisant le caractère #. Le fichier de configuration doit être encodé en UTF-8.
| Exemple : le fichier META-INF/services/fr.jmdoudoux.dej.spi.MonService |
# implementation simple du service
fr.jmdoudoux.dej.spi.MonServiceSimple
# implementation complexe du service
fr.jmdoudoux.dej.spi.MonServiceComplexeAu runtime, une classe dédiée va regarder le contenu des fichiers de configuration contenus dans le sous-répertoire META-INF/services du jar.
Les services providers compilés doivent être ajoutés dans le classpath : une solution pratique est de les packager dans une archive jar dédiée. Cela permet de remplacer la ou les implémentations utilisées simplement en remplaçant le jar par celui qui contient la ou les nouvelles versions.
La classe java.util.ServiceLoader permet de rechercher, charger et utiliser un service provider défini dans un fichier de configuration.
La recherche se fait dans le classpath de l'application.
La classe java.util.ServiceLoader possède plusieurs méthodes dont :
La méthode load() est une fabrique d'une instance de ServiceLoad capable de charger les instances d'un service dont l'interface est fournie en paramètre.
La méthode loadlnstalled() effectue la recherche de providers uniquement dans le répertoire d'extension du JRE qui par défaut est son répertoire lib/ext.
Le chargement du provider peut se faire avec un classloader dédié fourni en paramètre de la méthode load() ou loadlnstalled().
| Exemple : |
package fr.jmdoudoux.dej.spi;
import java.util.Iterator;
import java.util.ServiceLoader;
public class MonApp {
public static void main(final String[] args) {
final MonService service;
final ServiceLoader<MonService> loader = ServiceLoader.load(MonService.class);
final Iterator<MonService> iterator = loader.iterator();
if (iterator.hasNext()) {
service = iterator.next();
service.executer();
}
}
}
L'exemple ci-dessus va utiliser le premier service trouvé lors de la recherche.
Si le service MonServicesSimple est packagé dans un jar avec le fichier META-INF/services/fr.jmdoudoux.dej.spi.MonService contenant
| Exemple : |
# implementation simple du service
fr.jmdoudoux.dej.spi.MonServiceSimpleL'exécution de la classe MonApp avec le jar dans le classpath affiche :
| Résultat : |
Mon service simple Si le service MonServiceComplexe est packagé dans un jar avec le fichier META-INF/services/fr.jmdoudoux.dej.spi.MonService contenant
| Exemple : |
# implementation complexe du service
fr.jmdoudoux.dej.spi.MonServiceComplexeL'exécution de la classe MonApp avec le jar dans le classpath affiche :
| Résultat : |
Mon service complexe Il est possible de parcourir l'iterator pour sélectionner un ou plusieurs services à utiliser.
| Exemple : |
package fr.jmdoudoux.dej.spi;
import java.util.Iterator;
import java.util.ServiceLoader;
public class MonApp {
public static void main(final String[] args) {
MonService service;
final ServiceLoader<MonService> loader = ServiceLoader.load(MonService.class);
final Iterator<MonService> iterator = loader.iterator();
while (iterator.hasNext()) {
service = iterator.next();
service.executer();
}
}
}
| Résultat : |
Mon service simple
Mon service complexe Par défaut, la classe ServiceLoader utilise un cache pour ne pas rechercher les implémentations à chaque fois. La classe ServiceLoader est final : elle ne peut donc pas être sous classée pour par exemple modifier l'emplacement de recherche des providers.
L'API est détaillée dans le chapitre «L'API Service Loader».
Il est fréquent d'entendre que 64 bits c'est mieux que 32 bits : c'est vrai pour certaines fonctionnalités mais pas toujours vrai pour une JVM.
Les JVM 32 et 64 bits diffèrent essentiellement par leur façon d'accéder à la mémoire et dans la quantité de mémoire qu'elles peuvent utiliser. Les JVM 32 bits possèdent une limite maximale de la taille du heap qui dépend du système d'exploitation et de l'implémentation mais elle varie généralement entre 1,5 et 2,5 gigaoctets.
Le grand intérêt d'utiliser une JVM 64 bits est de pouvoir utiliser un heap d'une taille bien supérieure à celle d'une JVM 32 bits. Cependant, il est important de prendre en compte que la même quantité de données occupera plus de mémoire dans une JVM 64 bits.
Les JVM Hotspot d'Oracle et J9 d'IBM sont proposées en version 32 et 64 bits.
Dans un navigateur, il faut installer la version 32 ou 64 bits de Java qui correspond à la version 32 ou 64 bits du navigateur. Même sur un Windows 64 bits, c'est un navigateur 32 bits qui est exécuté par défaut.
Les JVM 64 bits permettent d'utiliser une plus grande quantité de mémoire pour le heap. Généralement, cette mémoire est uniquement limitée par la mémoire physique disponible sur le système qui, en 64 bits, peut être de grande taille.
L'utilisation d'un système d'exploitation 64 bits peut cependant intrinsèquement offrir aussi des avantages non négligeables sur des fonctionnalités natives notamment pour des serveurs : c'est par exemple le cas pour les IO et pour les calculs en virgule flottante.
Sur une architecture 64 bits, les calculs sur des types primitifs long ou double sont plus rapides puisque toute leur valeur (stockée dans 64 bits) peut être chargée directement en une seule opération de lecture alors qu'il en faut deux sur une architecture 32bits.
Dans tous les autres cas, les performances pourront aussi être obtenues indirectement grâce au fait que le processeur (registre ou instructions spécifiques) et le système d'exploitation sont en 64 bits ou que la taille du heap permet une mise en cache plus importante des données ce qui limitera par exemple les échanges I/O ou réseau.
Généralement, un système d'exploitation 64 bits n'impose pas l'utilisation de processus 64 bits.
La taille des variables de type primitives reste la même sur une JVM 32 et 64 bits : c'est un des fondements même du bytecode pour assurer la portabilité de Java. Les spécifications de Java imposent la taille en octets des types primitifs : la taille d'une variable de type long ou double est déjà de 64 bits et une variable de type int ou float est toujours sur 32 bits.
L'utilisation d'une JVM 32 ou 64 bits n'a aucune incidence sur le code source Java. Il n'est d'ailleurs pas possible de demander la compilation en 64 bits du code source Java. Le bytecode est par définition indépendant de sa plate-forme d'exécution pour assurer sa portabilité. Chaque opérateur du bytecode repose sur un octet sur une JVM 32 et 64 bits. Sans utiliser de code natif, grâce à JNI, le bytecode s'exécute de façon identique sur une JVM 32 et 64 bits.
Intrinsèquement une JVM est définie pour être 32 bits. Ainsi l'utilisation d'une JVM 64 bits ne permettra pas de dépasser certaines limites comme par exemple le nombre maximum d'éléments dans un tableau dont l'index est stocké dans une variable 32 bits.
L'utilisation d'une JVM 64 bits n'améliore généralement pas les performances pures de la JVM sauf si elle est capable d'utiliser certaines caractéristiques du processeur comme des registres spécifiques.
Les JVM 64 bits d'Oracle et IBM (depuis la version 1.6) proposent une fonctionnalité qui permet de comprimer les références (compressed oops) : elle permet de réduire la taille des références. La compression des pointeurs de mémoire internes à la JVM permet de réduire la taille du heap nécessaire pour stocker une même quantité de données dans une JVM 32 et une 64 bits.
Plusieurs JVM possèdent des fonctionnalités similaires dont l'implémentation et les limitations notamment en termes de taille maximale de heap varient
L'utilisation de cette fonctionnalité limite la taille maximale du heap. Par exemple, sur une J9 d'IBM avec les compressed references, qui sont activées par défaut, la taille maximale du heap est à 28 Go.
L'utilisation des compressed oops ajoute cependant un léger overhead pour permettre de transformer les adresses réduites vers les adresses natives et vice versa. Cette légère dégradation des performances est due aux calculs réalisés pour compresser sur 4 octets et décompresser sur 8 octets les pointeurs car physiquement sur la machine les pointeurs sont sur 64 bits.
L'option -XX:+UseCompressedOops de la JVM Hotspot 64 bits permet de demander la compression de la taille des pointeurs sur 32 bits ce qui réduit l'empreinte mémoire occupée par une même quantité de données dans le heap : au lieu d'utiliser la taille native d'un pointeur, elle compresse cette taille pour être équivalente à celle requise sur une JVM 32 bits.
Cette option n'est utilisable que si la taille maximale du heap est inférieure à 32 Go qui correspond à la taille maximale adressable avec des pointeurs 32 bits. Elle permet l'utilisation de heaps de plus grande taille qu'une JVM 32 bits tout en utilisant une taille de pointeurs sur 4 octets comme sur une JVM 32 bits.
L'utilisation de cette option n'est possible qu'à partir de la version Java 6 update 14 de la JVM Hotspot d'Oracle. L'option est activée par défaut à partir de la version Java 6 update 23 de la JVM Hotspot selon la taille maximale demandée au lancement de la JVM. Avec Java 7 64 bits, l'option est activée par défaut quand l'option -Xmx n'est pas précisée et quand la taille précisée par l'option -Xmx est inférieure à 32 Go.
Il n'est pas obligatoire d'utiliser une JVM 64bits sur un système d'exploitation 64 bits : il est même courant d'utiliser une JVM 32 bits sur un OS 64 bits. Il n'est pas possible de forcer l'utilisation en 32 bits d'une JVM 64 bits.
Généralement, les performances d'une même application exécutée sur une JVM 64 bits sont légèrement moins bonne que lors de son exécution sur une JVM 32 bits.
De plus la même quantité de données occupe plus de place dans le heap d'une JVM 64 bits par rapport à une JVM 32 bits.
Un processeur 32 bits ne représente les adresses que sur quatre octets : ainsi le nombre maximum d'adresses utilisables est de 2 puissance 32 ce qui correspond à espace d'adressage de 4294967296 octets soit 4 gigaoctets.
En théorie, il est donc possible d'adresser un peu moins de 4Go de mémoire sur un système 32 bits mais dans la pratique c'est toujours inférieur à 3 Go et même dans certains cas inférieur à 1,5 Go. Une partie de la mémoire est utilisée par le système d'exploitation et par d'autres applications. La fragmentation de la mémoire peut aussi réduire la taille maximale allouable. Ceci dépend du système d'exploitation et de l'implémentation de la JVM.
La limite la plus importante pour une JVM 32 bits est probablement sur Windows. Ceci est dû à la façon dont Windows 32 bits gère son espace mémoire. Le système d'exploitation Windows sépare ces 4 Go en deux parties : une utilisée par le noyau et la pagination de la mémoire et l'autre est utilisée pour les processus. Windows 32 bits fixe une limite de 2Go de mémoire pour chaque processus.
Le heap ne représente pas l'intégralité de la mémoire requise par une JVM : il y a aussi le processus chargé en mémoire, la permgen et différentes dll associées aux processus et chargées par le système. Ceci limite généralement la taille maximale du heap d'une JVM sous Windows 32 bits à moins de 1,6 Go. De plus l'implémentation Hotspot sous Windows requiert que l'espace mémoire utilisé par le tas soit d'un seul tenant, ce qui peut ajouter une contrainte sur la taille maximale du heap utilisable et encore diminuer sa valeur.
Pour parer à cette limitation, Windows propose l'API AWE qui permet à un processus d'utiliser plus de 3 Go de mémoire. Cette fonctionnalité présente une contrainte : le process doit être compilé avec cette API pour pouvoir l'exploiter. Cependant le choix a été fait de ne pas utiliser cette API dans la JVM Hotspot.
Sous un Windows 32 bits avec une JVM JRockit, il est possible d'allouer jusqu'à 2,8 Go de heap grâce notamment à la gestion de la mémoire qui autorise le morcellement.
Une implémentation 64 bits d'une JVM est prévue pour s'exécuter dans un système d'exploitation 64 bits sur une machine avec un processeur 64 bits.
L'utilisation d'une JVM 64 bits implique généralement :
L'intérêt principal d'utiliser une JVM 64 bits concerne la possibilité d'utiliser un heap de grande taille.
| Résultat : |
C:\Users\jm>java
-Xms4096m -Xmx24096m -version\n
java version "1.7.0_15"\n
Java(TM) SE Runtime Environment (build 1.7.0_15-b03)\n
Java HotSpot(TM) 64-Bit Server VM (build 23.7-b01, mixed mode)L'adressage d'une plus grande quantité de mémoire implique une légère dégradation des performances et une augmentation de l'espace mémoire requis pour stocker une même quantité de données. Ceci est lié au fait qu'une référence requiert 8 octets dans une JVM 64 bits contre seulement 4 octets pour une JVM 32bits. Il faut donc plus de mémoire pour stocker la même quantité d'objets sur une JVM 64 bits.
Dans une JVM 64 bits, la taille d'un pointeur sur un objet est doublée par rapport au même pointeur dans une JVM 32 bits et la taille du header d'un objet est aussi plus importante. Dans une JVM 32 bits, la référence d'un objet nécessite 4 octets et le header d'un objet nécessite 8 octets. Dans une JVM 64 bits, le header d'un objet est de 12 octets et la référence d'un objet nécessite 8 octets.
Plus le nombre d'objets est important dans la JVM, plus leur taille dans une JVM 64 bits sera importante par rapport à la taille requise dans une JVM 32 bits.
Une taille de heap importante peut avoir des effets bénéfiques : par exemple, la quantité de données en cache peut être augmentée. Mais elle présente aussi des inconvénients : par exemple, plus la taille du heap est importante plus long sera le temps nécessaire au ramasse-miettes pour effectuer ses traitements.
L'exécution du ramasse-miettes sur un heap plus grand augmente le temps de pause requis pour effectuer ses traitements. Plus la taille du heap augmente, moins le ramasse-miettes effectue de full garbage collections mais la durée de leurs exécutions est plus longue.
Attention : l'utilisation d'un heap de grande taille dans une JVM 64 bits nécessite de prendre en compte que le temps de pause requis pour les full garbage collections soit plus long. Il est donc nécessaire d'optimiser la configuration de la JVM et du ramasse-miettes en particulier pour limiter la durée de ces temps de pause notamment en utilisant un algorithme de type concurrent ou parallèle. Ceux-ci pourront réaliser certaines de leurs actions dans des threads dédiés en concurrence ou en parallèle avec l'exécution de l'application ce qui permettra de réduire ces temps de pause.
Avec une JVM Hotspot, il est recommandé d'utiliser des ramasse-miettes de type Parallel ou Concurrent pour des heaps dont la taille dépasse les 2 Go ceci afin de limiter l'overhead induit par les traitements de récupération de la mémoire inutilisée notamment :
Un second effet indirect de l'augmentation de la taille du heap est qu'il est possible d'avoir aussi plus de threads puisque chacun d'eux à besoin d'un petit espace pour stocker sa pile.
Dans une JVM 32 bits, le nombre de threads qu'il est possible de lancer est généralement de l'ordre du millier. Dans une JVM 64 bits, il est possible de lancer une centaine de milliers de threads avec la mémoire nécessaire.
La taille de la pile de chaque thread est cependant plus importante sur une JVM 64 bits que sur une 32 bits. Cette taille par défaut varie selon le système d'exploitation et l'implémentation de la JVM mais elle est en générale de 1024Ko pour une JVM 64 bits et de 320Ko ou 512Ko pour une JVM 32 bits.
Une bibliothèque native 32 bits ne peut être chargée que dans une JVM 32 bits, idem pour une bibliothèque 64 bits qui ne peut être chargée que dans une JVM 64 bits. En revanche, il n'est pas possible de charger une bibliothèque 32 bits dans une JVM 64 bits.
L'utilisation de code natif dans une JVM doit donc correspondre : du code natif 32 bits doit être recompilé en 64 bits pour pouvoir être utilisé dans une JVM 64 bits.
Le choix d'utiliser une JVM 64 bits est généralement dicté par le besoin d'une taille de heap importante (supérieure à la taille maximale allouable à une JVM 32 bits) et/ou par le besoin d'utiliser des bibliothèques natives compilées en 64 bits.
L'utilisation d'une JVM 64 bits peut être intéressante si l'application réalise beaucoup de calculs avec des variables de type long ou double ou si elle a besoin de faire beaucoup d'I/O.
Si le heap requis est compris entre 2Go et 4Go, il peut être intéressant d'utiliser une JVM 32 bits sur un système d'exploitation 64 bits.
Dans les autres cas, une JVM 32 bits doit pouvoir répondre aux besoins.
Par exemple, le tableau ci-dessous aide à choisir la JVM Hotspot à utiliser selon le système d'exploitation et la taille du heap souhaitée :
|
Système d'exploitation |
Taille du heap |
JVM |
|
Windows |
< 1,4 Go |
32 bits |
|
Windows 64 bits |
> 1,4 Go et < 32 Go |
64 bits avec -XX :+UseCompressedOops |
|
Windows 64 bits |
> 32 Go |
64 bits |
|
Linux |
< 2 Go |
32 bits |
|
Linux 64 bits |
> 2 Go et < 32 Go |
64 bits avec -XX :+UseCompressedOops |
|
Linux |
> 32 Go |
64 bits |
Une JVM 64 bits est particulièrement adaptée pour des applications manipulant de très grandes quantités de données :
Pour connaitre le mode de fonctionnement d'une JVM, il suffit de la lancer avec l'option -version. La version 32 bits ne fournie aucune information explicite sur l'architecture alors que la version 64 bits la précise clairement.
| Résultat : |
C:\Users\jm>java -version\n
java version "1.7.0_15"\n
Java(TM) SE Runtime Environment (build 1.7.0_15-b03)\n
Java HotSpot(TM) 64-Bit Server VM (build 23.7-b01, mixed mode)
C:\Users\jm>cd C:\Program Files (x86)\Java\jdk1.7.0_15\bin
C:\Program Files (x86)\Java\jdk1.7.0_15\bin>java -version
java version "1.7.0_15"
Java(TM) SE Runtime Environment (build 1.7.0_15-b03)
Java HotSpot(TM) Client VM (build 23.7-b01, mixed mode, sharing)La JVM Hotspot propose les options -d32 et -d64 mais elles sont informatives et ne fonctionnent pas correctement sur Windows XP.
Elles ne permettent pas de forcer le mode de fonctionnement de la JVM.
| Résultat : |
C:\Users\jm>java -version\n
java version "1.7.0_15"\n
Java(TM) SE Runtime Environment (build 1.7.0_15-b03)\n
Java HotSpot(TM) 64-Bit Server VM (build 23.7-b01, mixed mode)\n
C:\Users\jm>java -d32 -version\n
Error: This Java instance does not support a 32-bit JVM.\n
Please install the desired version.Normalement, le code Java ne devrait jamais dépendre de cette propriété pour permettre la mise en oeuvre de « write once, run everywhere ».
Elle peut cependant être utile pour conditionner le chargement dynamique d'une bibliothèque native.
Il est possible de consulter la valeur de la propriété sun.arch.data.model d'une JVM Hotspot pour déterminer si la JVM est 32 ou 64 bits.
| Exemple : |
package fr.jmdoudoux.dej;
public class TestJVM3264 {
public static void main(final String[] args) {
System.out.println(System.getProperty("sun.arch.data.model"));
}
}La propriété vaut «32» si la JVM est une 32 bits et «64» si la JVM est une 64 bits ou «unknown» si la valeur n'est pas définie.
Il est aussi possible de vérifier la valeur de la propriété «os.arch» de la JVM qui renvoie une chaîne de caractères précisant l'architecture de la plate-forme.
La valeur est «x86» sur une machine avec un Windows 32 bits.
|
|
|
|
|
|
||
| Développons en Java v 2.40 Copyright (C) 1999-2023 Jean-Michel DOUDOUX. | |||||||