v 2.40 Copyright (C) 1999-2023 Jean-Michel DOUDOUX.
")
")




| Développons en Java v 2.40 Copyright (C) 1999-2023 Jean-Michel DOUDOUX. |
|||||||
|
|
|
|
|
|
||
 |
 |
 |
| Niveau : | |
DOM est l'acronyme de Document Object Model. C'est une spécification du W3C pour proposer une API qui permet de modéliser, de parcourir et de manipuler un document XML.
Le principal rôle de DOM est de fournir une représentation mémoire d'un document XML sous la forme d'un arbre d'objets et d'en permettre la manipulation (parcours, recherche et mise à jour)
A partir de cette représentation (le modèle), DOM propose de parcourir le document mais aussi de pouvoir le modifier. Ce dernier aspect est l'un des aspects les plus intéressants de DOM.
DOM est défini pour être indépendant du langage dans lequel il sera implémenté. DOM n'est qu'une spécification qui pour être utilisée doit être implémentée par un éditeur tiers.
Il existe plusieurs versions de DOM nommées «niveaux» :
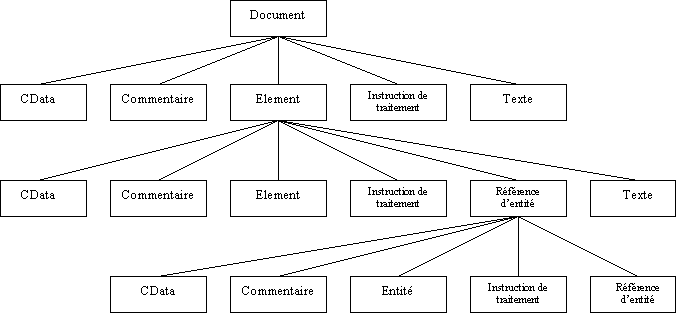
Chaque élément qui compose l'arbre possède un type. Selon ce type, l'élément peut avoir certains éléments fils comme le montre le schéma ci-dessus. Le premier élément est le document encapsulé dans l'interface Document
Toutes les classes et interfaces sont regroupées dans le package org.w3c.dom
Ce chapitre contient plusieurs sections :
Chaque type d'entité qui compose l'arbre est défini dans une interface. L'interface de base est l'interface Node dont plusieurs autres interfaces héritent.
Chaque élément de l'arbre est un noeud encapsulé dans l'interface org.w3c.dom.Node ou dans une de ses interfaces filles.
L'interface définit plusieurs méthodes :
|
Méthode |
Rôle |
|
short getNodeType() |
Renvoyer le type du noeud |
|
String getNodeName() |
Renvoyer le nom du noeud |
|
String getNodeValue() |
Renvoyer la valeur du noeud |
|
NamedNodeList getAttributes() |
Renvoyer la liste des attributs ou null |
|
void setNodeValue(String) |
Mettre à jour la valeur du noeud |
|
boolean hasChildNodes() |
Renvoyer un booléen qui indique si le noeud a au moins un noeud fils |
|
Node getFirstChild() |
Renvoyer le premier noeud fils du noeud ou null |
|
Node getLastChild() |
Renvoyer le dernier noeud fils du noeud ou null |
|
NodeList getChildNodes() |
Renvoyer une liste des noeuds fils du noeud ou null |
|
Node getParentNode() |
Renvoyer le noeud parent du noeud ou null |
|
Node getPreviousSibling() |
Renvoyer le noeud frère précédent |
|
Node getNextSibling() |
Renvoyer le noeud frère suivant |
|
Document getOwnerDocument() |
Renvoyer le document dans lequel le noeud est inclus |
|
Node insertBefore(Node, Node) |
Insèrer le premier noeud fourni en paramètre avant le second noeud |
|
Node replaceNode(Node, Node) |
Remplacer le second noeud fourni en paramètre par le premier |
|
Node removeNode(Node) |
Supprimer le noeud fourni en paramètre |
|
Node appendChild(Node) |
Ajouter le noeud fourni en paramètre aux noeuds enfants du noeud courant |
|
Node cloneNode(boolean) |
Renvoyer une copie du noeud. Le booléen fourni en paramètre indique si la copie doit inclure les noeuds enfants |
Tous les différents noeuds qui composent l'arbre héritent de cette interface. La méthode getNodeType() permet de connaître le type du noeud. Le type est très important car il permet de savoir ce que contient le noeud.
Le type de noeud peut être :
|
Constante |
Valeur |
Rôle |
|
ELEMENT_NODE |
1 |
Elément |
|
ATTRIBUTE_NODE |
2 |
Attribut |
|
TEXT_NODE |
3 |
Texte |
|
CDATA_SECTION_NODE |
4 |
Section de type CData |
|
ENTITY_REFERENCE_NODE |
5 |
Réference d'entité |
|
ENTITY_NODE |
6 |
Entité |
|
PROCESSING_INSTRUCTION_NODE |
7 |
Instruction de traitement |
|
COMMENT_NODE |
8 |
Commentaire |
|
DOCUMENT_NODE |
9 |
Racine du document |
|
DOCUMENT_TYPE_NODE |
10 |
Document |
|
DOCUMENT_FRAGMENT_NODE |
11 |
Fragment de document |
|
NOTATION_NODE |
12 |
Notation |
Cette interface définit une liste ordonnée de noeuds suivant l'ordre du document XML. Elle définit deux méthodes :
|
Méthode |
Rôle |
|
int getLength() |
Renvoie le nombre de noeuds contenus dans la liste |
|
Node item(int) |
Renvoie le noeud dont l'index est fourni en paramètre |
Cette interface définit les caractéristiques pour un objet qui sera la racine de l'arbre DOM. Elle hérite de l'interface Node. Un objet de type Document possède toujours un type de noeud DOCUMENT_NODE.
|
Méthode |
Rôle |
|
DocumentType getDocType() |
Renvoyer les informations sur le type de document |
|
Element getDocumentElement() |
Renvoyer l'élément racine du document |
|
NodeList getElementsByTagNames(String) |
Renvoyer une liste des éléments dont le nom est fourni en paramètre |
|
Attr createAttributes(String) |
Créer un attribut dont le nom est fourni en paramètre |
|
CDATASection createCDATASection(String) |
Créer un noeud de type CDATA |
|
Comment createComment(String) |
Créer un noeud de type commentaire |
|
Element createElement(string) |
Créer un noeud de type élément dont le nom est fourni en paramètre |
Cette interface définit des méthodes pour manipuler un élément et en particulier les attributs d'un élément. Un élément dans un document XML correspondant à un tag. L'interface Element hérite de l'interface Node.
Un objet de type Element à toujours pour type de noeud ELEMENT_NODE
|
Méthode |
Rôle |
|
String getAttribute(String) |
Renvoyer la valeur de l'attribut dont le nom est fourni en paramètre |
|
removeAttribut(String) |
Supprimer l'attribut dont le nom est fourni en paramètre |
|
setAttribut(String, String) |
Modifier ou créer un attribut dont le nom est fourni en premier paramètre et la valeur en second |
|
String getTagName() |
Renvoyer le nom du tag |
|
Attr getAttributeNode(String) |
Renvoyer un objet de type Attr qui encapsule l'attribut dont le nom est fourni en paramètre |
|
Attr removeAttributeNode(Attr) |
Supprimer l'attribut fourni en paramètre |
|
Attr setAttributNode(Attr) |
Modifier ou créer un attribut |
|
NodeList getElementsByTagName(String) |
Renvoyer une liste des noeuds enfants dont le nom correspond au paramètre fourni |
Cette interface définit des méthodes pour manipuler les données de type PCDATA d'un noeud.
|
Méthode |
Rôle |
|
appendData() |
Ajouter le texte fourni en paramètre aux données courantes |
|
getData() |
Renvoyer les données sous la forme d'une chaîne de caractères |
|
setData() |
Permettre d'initialiser les données avec la chaîne de caractères fournie en paramètre |
Cette interface définit des méthodes pour manipuler les attributs d'un élément.
Les attributs ne sont pas des noeuds dans le modèle DOM. Pour pouvoir les manipuler, il faut utiliser un objet de type Element.
|
Méthode |
Rôle |
|
String getName() |
Renvoyer le nom de l'attribut |
|
String getValue() |
Renvoyer la valeur de l'attribut |
|
String setValue(String) |
Mettre la valeur à celle fournie en paramètre |
Cette interface permet de caractériser un noeud de type commentaire.
Cette interface étend simplement l'interface CharacterData. Un objet qui implémente cette interface générera un tag de la forme <!-- --> .
Cette interface permet de caractériser un noeud de type Text. Un tel noeud représente les données d'un tag ou la valeur d'un attribut.
Pour pouvoir utiliser un arbre DOM représentant un document, il faut utiliser un parseur qui implémente DOM. Ce dernier va parcourir le document XML et créer l'arbre DOM correspondant. Le but est d'obtenir un objet qui implémente l'interface Document car cet objet est le point d'entrée pour toutes les opérations sur l'arbre DOM.
Avant la définition de JAXP par Sun, l'instanciation d'un parseur était spécifique à chaque implémentation.
| Exemple : utilisation de Xerces sans JAXP |
package fr.jmdoudoux.dej.testdom;
import org.apache.xerces.parsers.*;
import org.w3c.dom.*;
public class TestDOM2 {
public static void main(String[] args) {
Document document = null;
DOMParser parser = null;
try {
parser = new DOMParser();
parser.parse("test.xml");
document = parser.getDocument();
} catch (Exception e) {
e.printStackTrace();
}
}
}JAXP permet, si le parseur respecte ses spécifications, de l'instancier de façon normalisée.
| Exemple : utilisation de Xerces avec JAXP |
package fr.jmdoudoux.dej.testdom;
import org.w3c.dom.*;
import javax.xml.parsers.*;
public class TestDOM1 {
public static void main(String[] args) {
Document document = null;
DocumentBuilderFactory factory = null;
try {
factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
document = builder.parse("test.xml");
} catch (Exception e) {
e.printStackTrace();
}
}
}L'utilisation de JAXP est fortement recommandée.
Remarque : JAXP est détaillé dans une des sections suivantes de ce chapitre.
Un document XML peut être représenté par une vue à plat ou arborescente. DOM Level 2 propose plusieurs interfaces pour permettre la navigation dans un document XML décrites dans la recommandation Traversal.
Le parcours peut être fait de deux manières différentes :
Il est possible d'appliquer un filtre lors des parcours.
Toutes les interfaces sont contenues dans le package org.w3c.dom.traversal.
L'interface DocumentTraversal est le point de départ pour les objets qui vont permettre le parcours du document XML.
L'interface définit deux méthodes :
|
Méthode |
Rôle |
|
NodeIterator createNodeIterator(Node root, int whatToShow, NodeFilter filter, boolean entityReferenceExpansion) |
Renvoyer une instance de type NodeIterator permettant le parcours de la sous-arborescence à partir du noeud fourni |
|
TreeWalker createTreeWalker(Node root, int whatToShow, NodeFilter filter, boolean entityReferenceExpansion) |
Renvoyer une instance de type TreeWalker permettant le parcours de la sous-arborescence à partir du noeud fourni |
Les deux méthodes attendent les mêmes paramètres :
La spécification ne précise pas comment obtenir une instance de type DocumentTraversal : dans la plupart des implémentations, l'objet de type document implémente aussi l'interface DocumentTraversal.
L'interface NodeIterator définit des méthodes pour parcourir les éléments d'un document XML.
|
Méthode |
Rôle |
|
void detach() |
Détacher le NodeIterator de l'ensemble des noeuds qu'il parcourt. L'état du NodeIterator devient invalide |
|
NodeFilter getFilter() |
Obtenir le filtre de type NodeFilter |
|
Node getRoot() |
Obtenir le noeud initial du parcours |
|
int getWhatToShow() |
Obtenir une représentation du ou des types de noeuds qui seront obtenus lors du parcours |
|
Node nextNode() |
Renvoyer le noeud suivant dans le parcours |
|
Node previousNode() |
Renvoyer le noeud précédent dans le parcours |
Le parcours se fait en utilisant un itérateur qui permet d'obtenir chacun des noeuds à tour de rôle.
| Exemple : |
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.traversal.DocumentTraversal;
import org.w3c.dom.traversal.NodeFilter;
import org.w3c.dom.traversal.NodeIterator;
public class TestNodeIterator {
public static void main(String[] args) {
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder loader = factory.newDocumentBuilder();
Document document = loader.parse("livres.xml");
DocumentTraversal traversal = (DocumentTraversal) document;
NodeIterator iterator = traversal.createNodeIterator(
document.getDocumentElement(), NodeFilter.SHOW_ELEMENT, null, true);
for (Node n = iterator.nextNode(); n != null; n = iterator.nextNode()) {
System.out.println("Element: " + ((Element) n).getTagName());
}
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
Une instance de type TreeWalker permet de parcourir l'arborescence ou une sous-arborescence d'un document XML. Les noeuds obtenus lors de ce parcours peuvent être filtrés soit sur leur type en utilisant la propriété whatToShow ou en utilisant un filtre personnalisé.
L'interface TreeWalker définit plusieurs méthodes :
|
Méthode |
Rôle |
|
Node firstChild() |
Se déplacer sur le prochain noeud fils visible par le parcours et le renvoyer |
|
Node getCurrentNode() |
Obtenir le noeud courant dans le parcours |
|
NodeFilter getFilter() |
Obtenir le filtre associé |
|
Node getRoot() |
Obtenir le noeud initial du parcours |
|
int getWhatToShow() |
Obtenir une représentation du ou des types de noeuds qui seront obtenus lors du parcours |
|
Node lastChild() |
Se déplacer sur le dernier noeud visible par le parcours et le renvoyer |
|
Node nextNode() |
Se déplacer sur le prochain noeud visible par le parcours et le renvoyer |
|
Node nextSibling() |
Se déplacer sur le prochain noeud frère visible par le parcours et le renvoyer |
|
Node parentNode() |
Se déplacer sur le noeud père visible par le parcours et le renvoyer |
|
Node previousNode() |
Se déplacer sur le précédent noeud visible par le parcours et le renvoyer |
|
Node previousSibling() |
Se déplacer sur le précédent noeud frère visible par le parcours et le renvoyer |
|
void setCurrentNode(Node currentNode) |
Changer le noeud courant dans le parcours pour celui fourni en paramètre |
| Exemple : |
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.traversal.DocumentTraversal;
import org.w3c.dom.traversal.NodeFilter;
import org.w3c.dom.traversal.TreeWalker;
public class TestTreeWalker {
public static void main(String[] argv) throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder loader = factory.newDocumentBuilder();
Document document = loader.parse("livres.xml");
DocumentTraversal traversal = (DocumentTraversal) document;
TreeWalker walker = traversal.createTreeWalker(
document.getDocumentElement(), NodeFilter.SHOW_ALL, null, true);
walker.getRoot();
traverseLevel(walker, "");
}
private static final void traverseLevel(TreeWalker walker, String indent) {
Node noeud = walker.getCurrentNode();
if (noeud instanceof Element) {
System.out.println(indent + "- " + ((Element) noeud).getTagName());
for (Node n = walker.firstChild(); n != null; n = walker.nextSibling()) {
traverseLevel(walker, indent + " ");
}
}
walker.setCurrentNode(noeud);
}
}
L'interface NodeFilter définit des fonctionnalités de filtre pour définir les noeuds qui doivent être obtenus lors du parcours.
L'interface NodeFilter définit une seule méthode : short acceptNode(Node n).
La méthode renvoie une valeur de type short qui permet de préciser si le noeud est filtré ou non. L'interface NodeFilter définit trois constantes :
Aucune implémentation standard n'est fournie par l'API DOM.
Une implémentation de l'interface NodeFilter ne connait pas la structure de données parcourue ni la façon dont ces données sont parcourues. La seule qu'elle peut utiliser c'est le noeud fourni en paramètre.
| Exemple : |
import org.w3c.dom.Node;
import org.w3c.dom.traversal.NodeFilter;
public class MonNodeFilter implements NodeFilter {
@Override
public short acceptNode(Node n) {
if (n.getNodeName().contentEquals("auteur")) {
return FILTER_ACCEPT;
}
return FILTER_SKIP;
}
}Si une instance de type NodeFilter est fournie à un NodeIterator ou à un TreeWalker alors ils appliquent le filtre pour savoir si un noeud doit être retourné ou non. Si le filtre renvoie FILTER_ACCEPT alors le noeud est renvoyé lors du parcours sinon le prochain noeud du parcours est recherché pour lui appliquer le filtre.
| Exemple : |
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.traversal.DocumentTraversal;
import org.w3c.dom.traversal.NodeFilter;
import org.w3c.dom.traversal.TreeWalker;
public class TestTreeWalkerAvecFiltre {
public static void main(String[] argv) throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder loader = factory.newDocumentBuilder();
Document document = loader.parse("livres.xml");
DocumentTraversal traversal = (DocumentTraversal) document;
TreeWalker walker = traversal.createTreeWalker(
document.getDocumentElement(), NodeFilter.SHOW_ELEMENT,
new MonNodeFilter(), true);
Node noeud = null;
noeud = walker.nextNode();
while (noeud != null) {
System.out.println(noeud.getNodeName() + " : "
+ noeud.getChildNodes().item(0).getNodeValue());
noeud = walker.nextNode();
}
}
}
Un des grands intérêts du DOM est sa faculté de créer ou modifier l'arbre qui représente un document XML.
La méthode newDocument() de la classe DocumentBuilder renvoie une nouvelle instance d'un objet de type Document qui encapsule un arbre DOM vide.
Il faut a minima ajouter un tag racine au document XML. Pour cela, il faut appeler la méthode createElement() de l'objet Document en lui passant le nom du tag racine pour obtenir une référence sur le nouveau noeud. Il suffit ensuite d'utiliser la méthode appendChild() de l'objet Document en lui fournissant la référence sur le noeud en paramètre.
| Exemple : |
package fr.jmdoudoux.dej.testdom;
import org.w3c.dom.*;
import javax.xml.parsers.*;
public class TestDOM09 {
public static void main(String[] args) {
Document document = null;
DocumentBuilderFactory fabrique = null;
try {
fabrique = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = fabrique.newDocumentBuilder();
document = builder.newDocument();
Element racine = (Element) document.createElement("bibliotheque");
document.appendChild(racine);
} catch (Exception e) {
e.printStackTrace();
}
}
}
L'interface Document propose plusieurs méthodes createXXX pour créer des instances de différents types d'éléments. Il suffit alors d'utiliser la méthode appendChild() d'un noeud pour lui attacher un noeud fils.
| Exemple : |
Element monElement = document.createElement("monelement");
Element monElementFils = document.createElement("monelementfils");
monElement.appendChild(monElementFils);Pour ajouter un texte à un noeud, il faut utiliser la méthode createTextNode() pour créer un noeud de type Text et l'ajouter au noeud concerné avec la méthode appendChild().
| Exemple : |
Element monElementFils = document.createElement("monelementfils");
monElementFils.appendChild(document.createTextNode("texte du tag fils");
monElement.appendChild(monElementFils);Pour ajouter un attribut à un élément, il existe deux méthodes : setAttributeNode() et setAtribute().
La méthode setAttributeNode() attend un objet de type Attr qu'il faut préalablement instancier.
| Exemple : |
Attr monAttribut = document.createAttribute("attribut");
monAttribut.setValue("valeur");
monElement.setAttributeNode(monAttribut);La méthode setAttribut permet d'associer directement un attribut et sa valeur grâce aux paramètres fournis.
| Exemple : |
monElement.setAttribut("attribut","valeur");La création d'un commentaire se fait en utilisant la méthode createComment() de la classe Document.
Toutes ces actions permettent la création complète d'un arbre DOM représentant un document XML.
| Exemple : un exemple complet |
package fr.jmdoudoux.dej.testdom;
import org.w3c.dom.*;
import javax.xml.parsers.*;
public class TestDOM11 {
public static void main(String[] args) {
Document document = null;
DocumentBuilderFactory fabrique = null;
try {
fabrique = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = fabrique.newDocumentBuilder();
document = builder.newDocument();
Element racine = (Element) document.createElement("bibliotheque");
document.appendChild(racine);
Element livre = (Element) document.createElement("livre");
livre.setAttribute("style", "1");
Attr attribut = document.createAttribute("type");
attribut.setValue("broche");
livre.setAttributeNode(attribut);
racine.appendChild(livre);
livre.setAttribute("style", "1");
Element titre = (Element) document.createElement("titre");
titre.appendChild(document.createTextNode("Titre 1"));
livre.appendChild(titre);
racine.appendChild(document.createComment("mon commentaire"));
} catch (Exception e) {
e.printStackTrace();
}
}
}| Résultat : |
<?xml version="1.0" encoding="UTF-8"?>
<bibliotheque>
<livre style="1" type="broche">
<titre>Titre 1</titre>
</livre>
<!--mon commentaire-->
</bibliotheque>
Une fois un arbre DOM créé ou modifié, il est souvent utile de l'envoyer dans un flux (sauvegarde dans un fichier ou une base de données, envoi dans un message JMS ...).
Bizarrement, DOM Level 1 et 2 ne proposent rien pour réaliser cette tâche pourtant essentielle. Ainsi, chaque implémentation propose sa propre méthode en attendant des spécifications qui feront sûrement partie du DOM Level 3.
Xerces fournit la classe XMLSerializer qui permet de créer un document XML à partir d'un arbre DOM.
Xerces est téléchargeable sur le site web https://xerces.apache.org/xerces2-j/ sous la forme d'une archive de type zip qu'il faut décompresser dans un répertoire du système. Il suffit alors d'ajouter les fichiers xmlParserAPIs.jar et xercesImpl.jar dans le classpath.
| Exemple : |
package fr.jmdoudoux.dej.testdom;
import org.w3c.dom.*;
import javax.xml.parsers.*;
import org.apache.xml.serialize.*;
public class TestDOM10 {
public static void main(String[] args) {
Document document = null;
DocumentBuilderFactory fabrique = null;
try {
fabrique = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = fabrique.newDocumentBuilder();
document = builder.newDocument();
Element racine = (Element) document.createElement("bibliotheque");
document.appendChild(racine);
for (int i = 1; i < 4; i++) {
Element livre = (Element) document.createElement("livre");
Element titre = (Element) document.createElement("titre");
titre.appendChild(document.createTextNode("Titre "+i));
livre.appendChild(titre);
Element auteur = (Element) document.createElement("auteur");
auteur.appendChild(document.createTextNode("Auteur "+i));
livre.appendChild(auteur);
Element editeur = (Element) document.createElement("editeur");
editeur.appendChild(document.createTextNode("Editeur "+i));
livre.appendChild(editeur);
racine.appendChild(livre);
}
XMLSerializer ser = new XMLSerializer(System.out,
new OutputFormat("xml", "UTF-8", true));
ser.serialize(document);
} catch (Exception e) {
e.printStackTrace();
}
}
}| Résultat : |
<?xml version="1.0" encoding="UTF-8"?>
<bibliotheque>
<livre>
<titre>Titre 1</titre>
<auteur>Auteur 1</auteur>
<editeur>Editeur 1</editeur>
</livre>
<livre>
<titre>Titre 2</titre>
<auteur>Auteur 2</auteur>
<editeur>Editeur 2</editeur>
</livre>
<livre>
<titre>Titre 3</titre>
<auteur>Auteur 3</auteur>
<editeur>Editeur 3</editeur>
</livre>
</bibliotheque>
|
|
|
|
|
|
||
| Développons en Java v 2.40 Copyright (C) 1999-2023 Jean-Michel DOUDOUX. | |||||||